


Hey AI Product Leaders 👋
✨ Ready to level up with Agentic AI?
Last week, we broke down the foundations of AI workflows vs. agent — what they are, why they matter, and the tradeoff between reliability vs. agency. (Catch up here in case you missed it.)
This week, we’re going deeper with ReAct Agents, Multi-Agents, and Deep Agents — and why they’re the future of AI.
Quick Recap
✅ Workflows = predictable, code-driven, reliable
✅ Agents = autonomous, adaptive, but less reliable
✅ Agency = how much control an agent has to perceive, decide, and act
👉 AI PM takeaway: More agency = more flexibility, but less predictability. Your job? Balance the tradeoff depending on user needs + business value.
Agents in Plain English
Think of an agent as a smart colleague:
You give them a goal
They come up with an action plan
They ask you to approve it
Then they run the scripts, via tool use
Eventually, they’ll report back when they’re stuck or done
Not a single prompt → more like → an iterative worker bee 🐝.
Agents are emerging more in prod as LLMs mature across key capabilities:
understanding complex inputs
engaging in reasoning and planning
using tools reliably
and recovering from errors
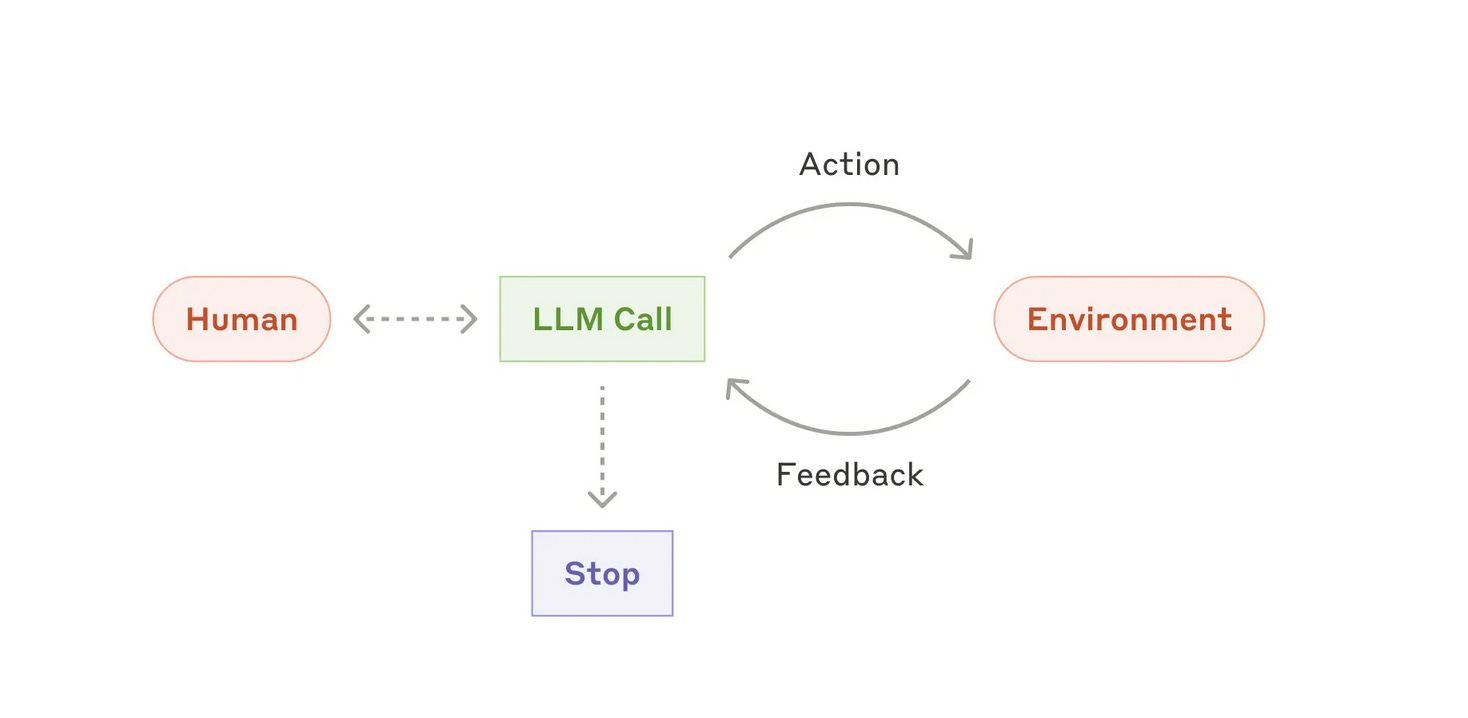
Agent runs (happy path)
Kickoff: Human provides the goal + necessary scope
Plan: Agent proposes steps + needed tools/data
Act: Executes steps with tools/APIs/MCPs
Observe: Reads outputs/logs; compares to goal
Checkpoint: Ask for human input if blocked/confused
Stop: Finish on success or hits safe stop (iteration/time/cost caps)
When to use agents
✅ Open-ended tasks with unknown step counts.
✅ Multi-tool workflows (code + APIs + search + UI).
✅ Trusted environments where autonomy saves time at scale.
When not to
❌ There’s a known, stable path → use a workflow.
❌ High-stakes with low tolerance for exploratory steps → constrain to deterministic flows.
Real use cases (for Agents)
Coding agent that tackles multi-file bug fixes (SWE-bench-style tasks).
Computer-use agent that operates across apps/OS to complete goals.
Guardrails that actually work
Context control: Only feed the model the right slices (docs, tickets, code spans).
Ground truth at every step: Trust tool outputs over model guesses.
Human-in-the-loop: Approval gates for plans, risky actions, or ambiguous results.
Stop conditions: Max iterations/time/cost; auto-abort on low confidence.
Evals & traces: Task-level pass/fail + step-level span checks so you can debug and improve.
Memory discipline: Persist only what’s reusable; avoid polluting future runs.
💡 The challenge with building reliable agentic systems is making sure the LLM has the appropriate context at each step.
💡 This includes both controlling the exact content that goes into the LLM, as well as running the appropriate steps to generate relevant output.
This is precisely where ReAct comes into play 👇
The ReAct Breakthrough ⚡
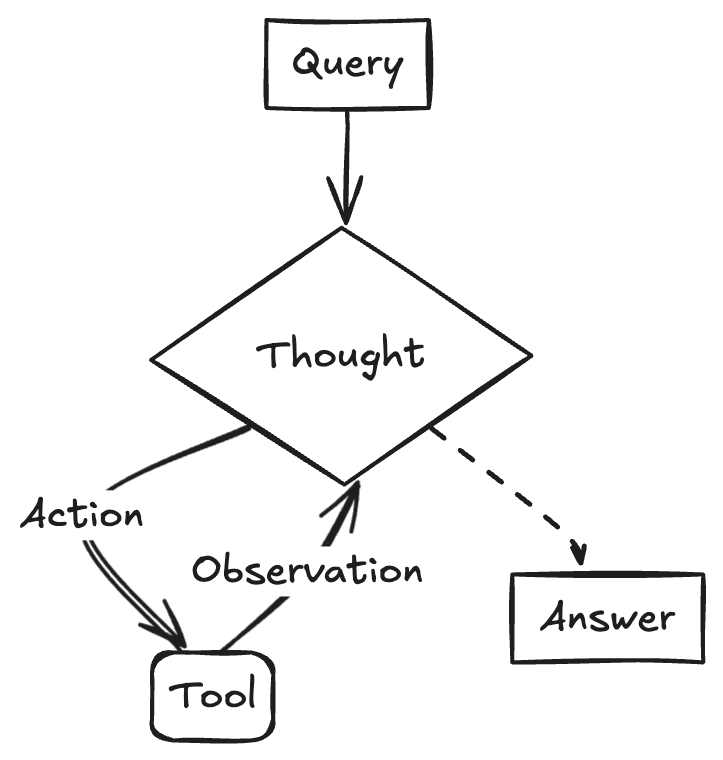
A ReAct agent interleaves thoughts via reasoning and actions via tool use step-by-step, in order to solve complex tasks, which proves useful for dealing with the complexities of multi-turn conversations.
Prior to the advent of ReAct, agentic capabilities for reasoning and acting were treated as two separate topics.
Princeton + Google Brain researchers flipped the script in their seminal paper, “REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS.” They uncovered a breakthrough method for using LLMs:
“…to generate both reasoning traces and task-specific actions in an interleaved manner, allowing for greater synergy between the two: reasoning traces help the model induce, track, and update action plans as well as handle exceptions, while actions allow it to interface with external sources, such as knowledge bases or environments, to gather additional information.”
ReACT Agents use thought → action → observation loops to:
Think through the problem
Decide what to do
Execute the action (via tool-calling)
Observe the results
Reflect + repeat until the goal is met
Why it matters
💡 The ReAct framework demonstrated its effectiveness over SOTA baselines, as well as improved human interpretability and trustworthiness.
💡 Multi-agent frameworks leverage multiple ReAct agents (as the building block) who work in concert within a network (or ‘swarm’) or are coordinated by a ‘supervisor.’
💡 Deep agents extend the ReACt framework by leaning more heavily into tool-driven reasoning — they don’t just plan + act, they chain tool calls with depth, building on each intermediate result until the task is complete.
Now that we’ve mastered the single-agent use case, let's talk about workflows with multiple agents 👇
Enter Multi-Agents
If one agent = an intelligent colleague, then multi-agents = an intelligent team.
As the name suggests, "Multi-agent" workflows contain multiple agents powered by language models that are connected in a specific manner.
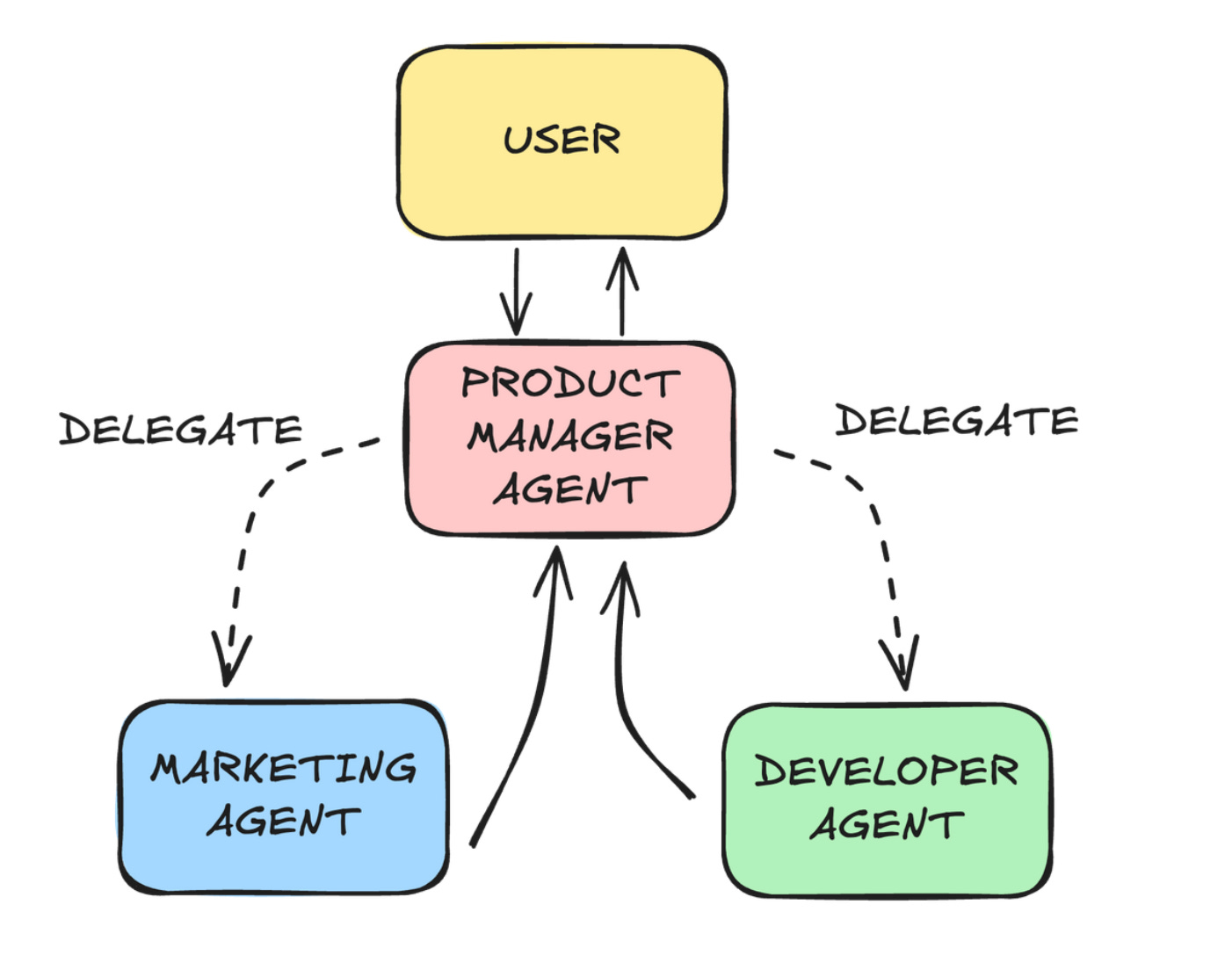
Imagine you want to design a website.
Designing a website involves many tasks, including writing specs, coding the backend, creating a brand, etc. Some tasks depend on others (specs come first), while others can happen in parallel (branding and coding).
If you give one agent too many tools and responsibilities, it will struggle to decide what to use and when. A better approach is to have multiple specialized agents — like a coding agent and a marketing agent — that work together to complete the job while being coordinated by a product manager agent.
(I am a little biased to this approach ;)
Benefits of multi-agents
As seen in the image above, multi-agents:
Scope tools + domains accordingly.
Split prompts intelligently.
Modularize design.
Multi-agent frameworks divide complex problems into manageable units of work.
There are multiple emerging design patterns for multi-agent systems. Let’s focus on the two most popular:
Swarm, or network agents, and
Supervisor agents.
Swarm Agents
Swarm agents work together in a network where each agent specializes in narrow domain knowledge and uses its own tools. Swarm agents pass tasks between each other to divide & conquer.
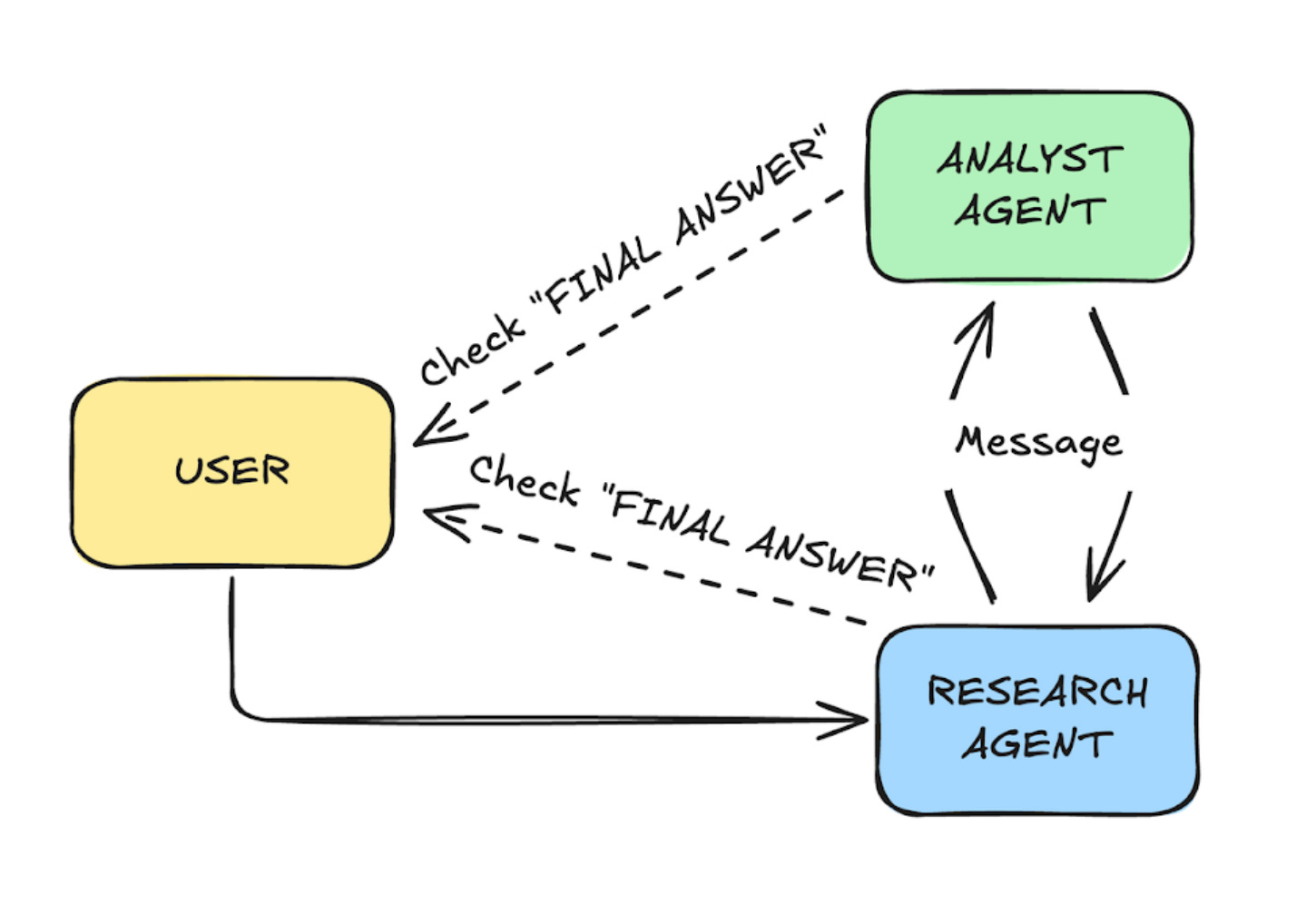
Imagine you want to analyze some stock data. In this example, two agents are working together collaboratively:
The research agent fetches stock summaries and data.
The analyst agent takes said data and plots it on a line graph.
⚠️ Caveat: While it’s easy to extend from a single agent, coordination overload can occur.
Challenges with the Swarm Approach
Agent Collaboration: These agents can get stuck in infinite loops, where neither can finish the task, but they keep passing the ball back and forth, expecting the other agent to succeed.
Choosing the right starter agent: Another limitation is the workflow requires selecting a starting agent (to route the request to).
✨ Solution: A third supervisor agent to coordinate the routing for the Win!
Supervisor Agents
Supervisor agents guide the process by delegating to other agents; agents can then take actions + make decisions with autonomy.
Back to our website → the supervisor agent acts as a product manager, who acts as the go-between for coding and marketing agents.
User input first reaches the supervisor, which is responsible for enabling collaboration between the agents and coalescing their respective outputs.
The supervisor decides how tasks should be delegated; other agents hand back to the supervisor, which determines if the task is done or whether the flow should continue.
💡 Supervisors may also decide a task doesn't require a tool call or delegation at all. In this case, the supervisor itself will provide a standard model response back to the user.
💡 Supervisors have a high degree of autonomy, including which agents to delegate to and when to end the flow.
💡 Supervisor agents can be thought of as agents whose tools are other agents!
😅 Sidebar – clearly, a developer made this diagram because they forgot to include a designer!
The Deep Agent Revolution🔥
Deep agents are a next-generation design pattern for agentic AI that go beyond simple tool use. They perform multi-step planning, and reflection — and they learn over time.
The next frontier in AI agents involves "deep" reasoning capabilities — agents that don't just follow predefined paths but can adapt, and learn to create entirely new approaches to solve problems.
They’re called “deep” because they operate over longer time horizons, and they have recursive reasoning + persistent memory, allowing them to solve more complex and layered problems.
The simplest kind of agent is just an LLM looping through tool calls. But this setup often creates “shallow” agents that struggle with longer, more complex tasks.
Deep agents in the wild
Agentic systems like Deep Research, Manus, and Claude Code are examples of Deep agents in production.
So what makes these agents good at going deep?
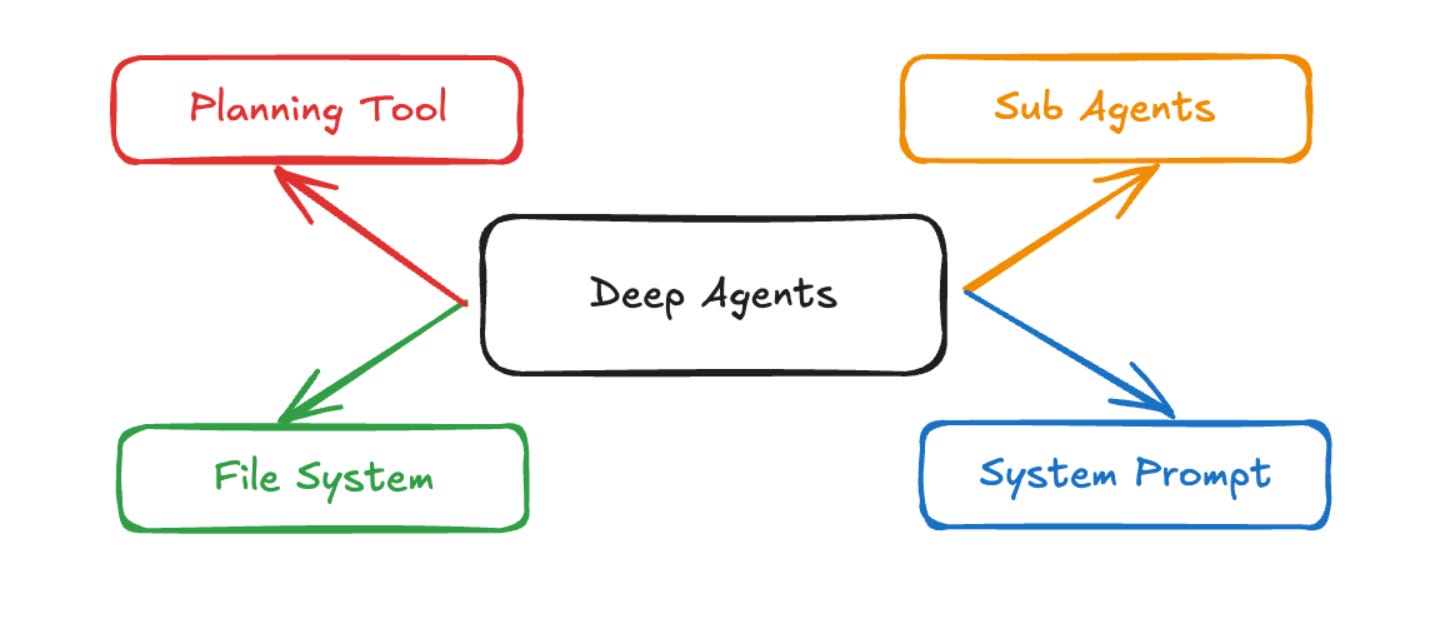
At the core, the algorithm is ReAct → it’s an LLM running in a loop that calls some tools. The difference is that Deep agents possess:
A detailed system prompt: Deep agents rely on long, carefully crafted system prompts.
Prompting still matters by the way…
In fact, most Agentic use cases I come across in Prod can be ~90% solutioned with just prompt (context) engineering + routing.
A planning tool: Claude Code uses a Todo list tool — ironically, it doesn’t do anything, but serves as context scaffolding to keep the agent on track.
A file system: Deep agents often accumulate large amounts of context, and file systems help manage that load.
The ability to spawn sub-agents: Claude Code can spawn sub-agents to break down tasks, which act as focused worker bees with narrower prompts (this helps manage context and go deeper into individual problems).
Deep agents are generally capable of breaking down complex use cases into manageable tasks and then executing over longer time horizons to accomplish their goal(s).
Langchain’s deepagents package was heavily inspired by Claude Code, which people were already using far more than just for coding.
Research and coding have become the two main use cases for Deep agents. Every major proprietary model provider now offers some form of Deep Research and async coding agents, and many startups and customers are building their own versions.
Example
Prompt: “Research and summarize the top 5 trends in generative AI this year.”
A shallow agent:
Googles a few links, summarizes, done
A deep agent:
Plans: break down into subtopics (LLMs, RAG, agents, etc.)
Retrieves multiple documents per topic
Evaluates the reliability of sources
Synthesizes relevant context across them
Reflects: “Did I miss anything?”
Writes a clean report
Stores references in memory for reuse
Why Deep Agents Matter
💡 Deep agents handle harder + longer tasks so you don’t have to.
By combining rich prompts, planning, sub-agents, and memory (via file systems), they avoid being “shallow” and can sustain reasoning, break down problems, and carry context over time.
In short, they’re what make agents useful beyond toy demos.
📚 Learn More (Sources)
🔗Langchain: LangGraph: Multi-Agent Workflows Blog
🔗Anthropic: Building Effective Agents Blog
🔗Phil Schmid: ReAct agent from scratch with Gemini 2.5 and LangGraph Blog
🔗Arxiv: "REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS" Paper
🔗DataCamp: Designing Agentic Systems with LangGraph
🔗DataCamp: Multi-Agent Systems with LangGraph
🔗Langchain: Benchmarking Single Agent Performance Blog