


👋 Hey, AI product leaders.
✨Ready to break into Agentic AI?
Last week, we leveled up by learning about agentic architectures, including react agents, multi-agents, and deep agents — what they are, why they matter, and why deep agents are taking the world by storm. (Catch up here in case you missed it.)
The week before that, we broke down the foundations of AI workflows vs. agents — and the tradeoff between reliability vs. agency. (Read all about it here.)
This week, we’re taking a step back… before we progress to the advanced topics of building scalable agentic systems that optimize for speed, security, and accuracy (agentic RAG, long-term memory, MCP, reasoning, context ENG, etc.), we must understand the fundamental ingredients (or components) that comprise agentic workflows.
TL;DR
90% of the use cases I come across in prod are well-suited for low-agency workflows (let that sink in) 🤔
Mastering the basics of agentic AI actually gets you to value realization much faster than slapping on an agent and… ‘let ‘er rip!’
So it’s important to WALK AWAY FROM THIS POST with a fundamental understanding of how to optimize your AI workflows, with:
Prompt ENG
Routing
Basic RAG
Fine-tuning
Hyper-parameter tuning
“Success in the LLM space isn't about building the most sophisticated system. It's about building the right system for your needs. Start with simple prompts, optimize them with comprehensive evaluation, and add multi-step agentic systems only when simpler solutions fall short.”
— Anthropic
Well-defined prompts achieve ~80% accuracy for most use cases
Prompts are the tools we use to communicate our requests to generative models.
💡 Prompting is more important than ever now with the advent of context engineering.
💡 Prompts are treated as production assets with version control tied to experimentation. Testing prompt changes as a means to improve eval metrics.
Anatomy of a decent prompt
Role: Define a clear role for the agent. The more specific the role, the more relevant the output (ie. ‘You are a world-class customer support triaging agent…’)
Goal/Task: State the exact task that you want the model to perform + the outcome you want it to achieve. Be explicit about the desired action or outcome.
Context: Provide all the necessary info that the model needs to perform well (background details, historical context, steps, and examples).
Few-shot Examples: Give the model examples to imitate (good + bad), then allow it to reference the examples to predict on unseen data.

Reasoning Instructions: Prompt it to think through the problem. Request that GPT-5 ‘THINK HARDER’ and/or explain its thought process, or follow a logical chain of thought before providing the final response.
Output Format: How you want the answer presented. List the format clearly (bullet points, tables, JSON).
Guardrails: Set boundaries for the response + stopping conditions. Such as limiting the length or ending at a certain step. AI is powerful, but without constraints, it can go off track. They might hallucinate, loop endlessly, or make bad calls. Guardrails ensure that AI stays on track and maintains quality standards.

Examples of useful guardrails include:
● Limiting tool usage: Prevent an agent from overusing APIs or generating irrelevant queries.
● Setting validation checkpoints: Ensure outputs meet predefined criteria before moving to the next step.
● Establishing fallback mechanisms: If an agent fails to complete a task, another agent or human reviewer can intervene.
Think of routing as the LLM’s ability to ‘pick the right tool for the job
Routing is the agent’s ability to interpret a request and determine the correct tool that should be used to resolve it.
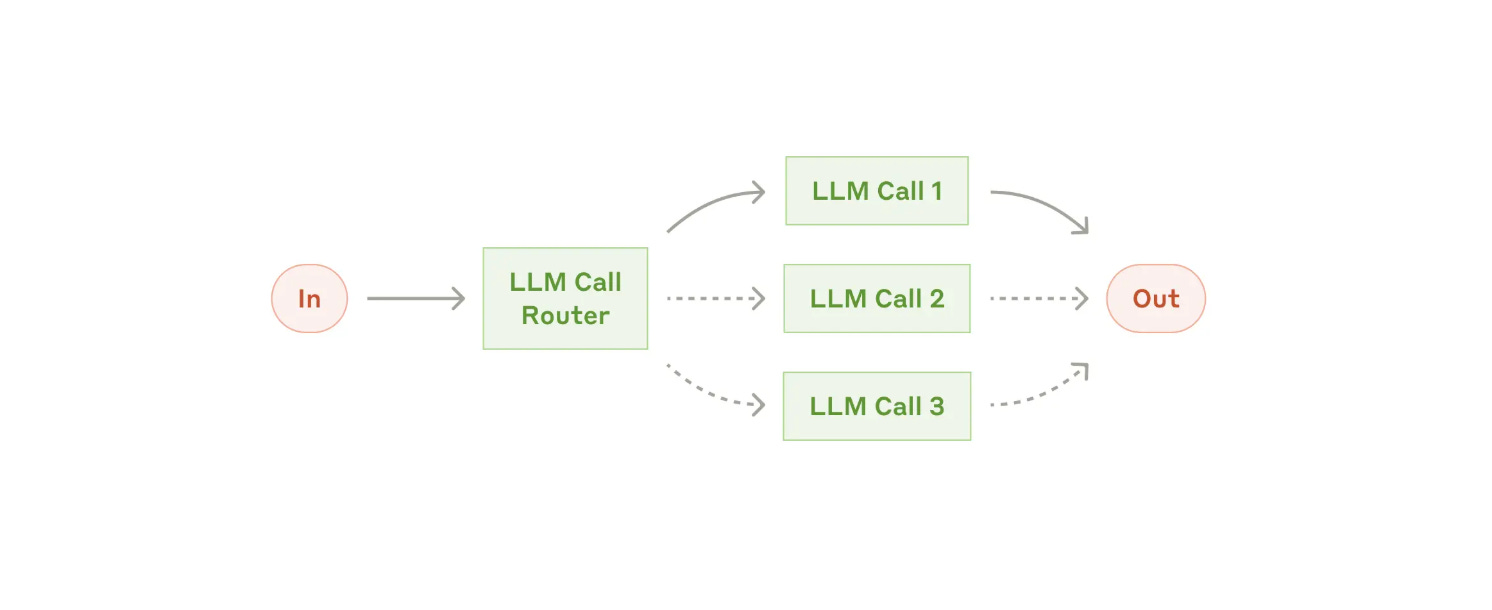
An agent is only as good as the tools it calls. Good routing = the right skill + the right parameters.
✅ Did the agent choose the right function?
✅ Did it extract the right parameters?
Routing can take the form of an LLM, an NLP- or an ML-based classifier, or even deterministic code.
Some frameworks (like LangGraph) distribute routing logic throughout the graph, while others use a centralized planner.
👍 Routing should be based on the user's intent, relative to the data, tool, or action that must be performed to sufficiently respond to the prompt.
For example, does the user want a full travel itinerary, or do they simply want to know what the weather forecast is for MIA during their stay? Or do they want the AI to actually book the flight on their behalf?
Depending on the context, the routing will be different.
Last week, when we talked about multi-agents, we established that supervisors can treat other agents as tools. (This is where routing comes into play) 👇
Take the example of customer support: based on the intent, the triaging agent (supervisor) can route the query to either a billing agent or a troubleshooting agent, depending on whether the customer’s query was about troubleshooting a device or about their bill.
Even RAG can be naive
Take that Bayes!
👉 In short: Naïve RAG = Top-k retrieval + context stuffing + single-shot generation.
How does RAG work?
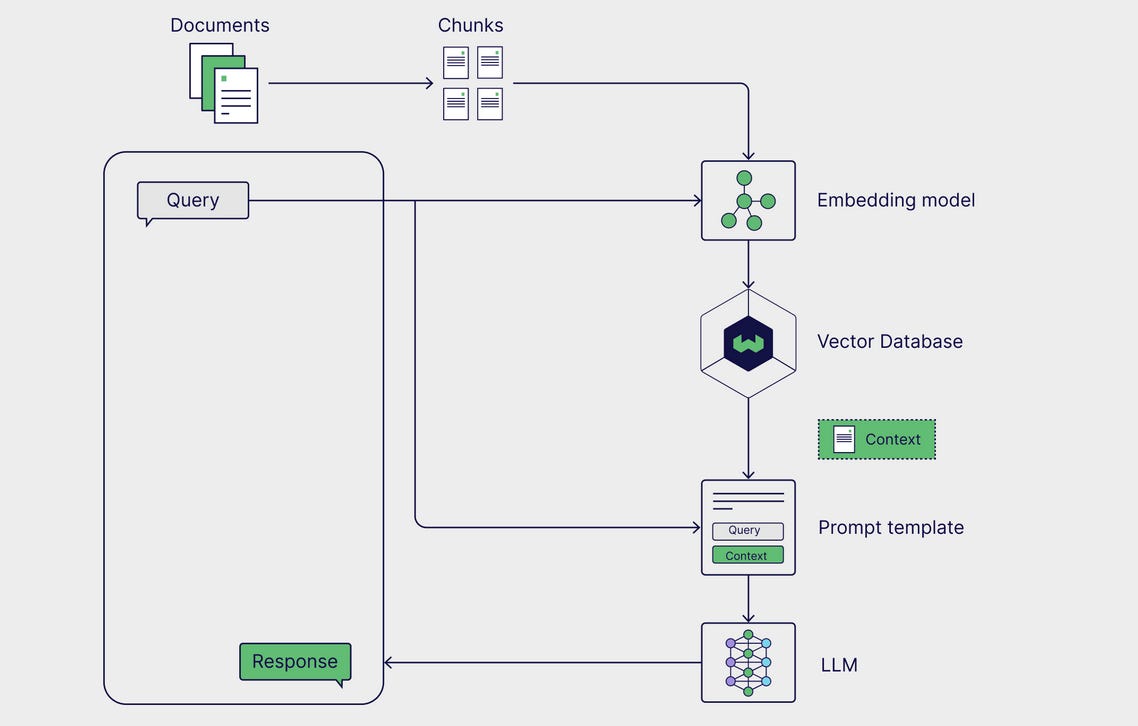
RAG is a multi-step framework that works in two stages:
External knowledge is preprocessed and prep’d for retrieval during the ingestion stage.
During inference, the model retrieves the relevant data from the knowledge store + augments it with the user’s prompt, and generates a response.
Why RAG matters
Instead of relying only on the LLM’s internal training data, RAG lets the model retrieve relevant information from an external source (a vector database) and use it to generate more accurate, up-to-date, and grounded responses.
The basic parts of a RAG pipeline can be broken down into three components:
1. External knowledge source
Absent external knowledge, language models are limited to generating responses solely by relying on their training data. With RAG, external data is incorporated into the context window.
2. Prompt templates
Prompt templates generate normalized prompts, so that various queries + contexts can be injected. In a RAG pipeline, relevant data is retrieved from an external data source and inserted into the template, effectively augmenting the prompt. Prompt templates bridge the external data to the model, providing the model with contextually relevant info to generate accurate responses.
3. LLM
The final component in RAG is the language model, which is used to generate a final response to the user’s query. The augmented prompt, with info from the external KB, is sent to the model, which generates a response that combines the model's internal knowledge with the newly retrieved data.
Together, these components enable Gen AI apps to generate more accurate responses by leveraging task-specific data.
🔁 How RAG works (step-by-step)
User Prompt:
“Tell me about Claude Code TodoPlanner.”Retrieve:
Convert the query to an embedding (vector)
Search a vector database (like Pinecone, Weaviate, FAISS) for relevant docs
Retrieve top-N results
Augment:
Inject retrieved docs into the LLM prompt (usually in the context window)
Generate:
LLM reads the user prompt + retrieved context
Produces a grounded answer
Why it’s called ‘naïve’
No reranking or filtering → It just trusts the top-k retriever results.
No reasoning over multiple docs → Passages are pasted in, not synthesized intelligently.
No iterative refinement → Only one retrieval + one generation step.
Prone to hallucinations → If irrelevant docs are pulled in, the LLM may mix them with made-up info.
💡 RAG is the most complex use case of all the components mentioned in practice.
Why? Because in enterprise settings, different optimizations of RAG can lead to vastly different outcomes → meaning there’s a tradeoff between optimizing for security, speed, and accuracy.
Note — there are many different types of RAG architectures. Naive RAG only scratches the surface. I’m going to post a RAG Masterclass — you can hold me to it 👍
OH, AND RAG IS NOT DEAD PPL! Sorry, had to get that off my chest…
What is fine-tuning?
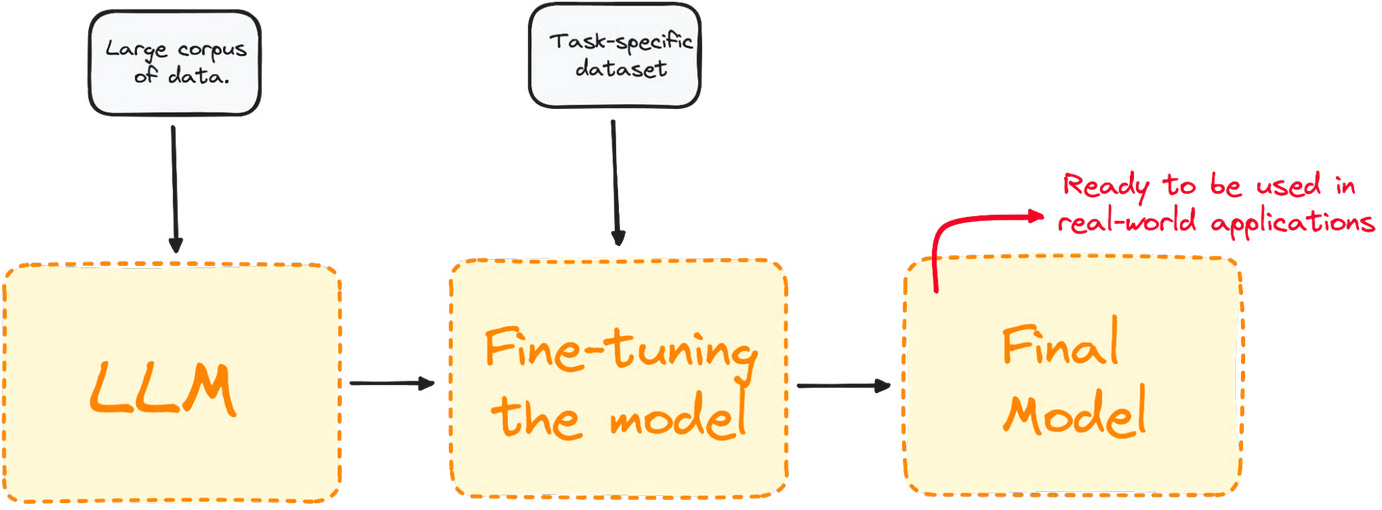
Fine-tuning is like taking a model that already speaks fluent English, and training it to:
Speak like a lawyer
Understand medical terminology
Write like your brand
Perform better at a specific task
How it works
Start with a base model (like GPT-5 or Claude 4.1 Sonnet)
Provide it with a custom dataset (e.g. customer support chats, financial documents, etc.)
Train it further using gradient descent on your data
The model learns patterns specific to your domain or goals
Types of fine-tuning
Supervised Fine-Tuning (SFT): Train on labeled input-output pairs.
LoRA (Low-Rank Adaptation): Train fewer parameters with less compute. Great for fast, cheap tuning.
⚠️ Considerations
Needs GPU resources
Risk of overfitting on small datasets
Requires clean, high-quality training data
Must monitor for bias and drift
Slower, needs infrastructure
Better when production use cases require quality
Can improve accuracy for specific tasks
RAG + fine-tuning = best of both worlds
Instead of picking one, leading teams now combine them:
Fine-tuning for reasoning + style:
Teach the model how to think in your domain (e.g., chain-of-thought for medical triage, tone for customer support).
Reduce prompt engineering overhead.
RAG for fresh, dynamic knowledge:
Retrieve up-to-date facts, docs, or records so the fine-tuned model isn’t limited by static training data.
Keep answers current without retraining every week.
Agentic workflows:
Fine-tuned LLM = “reasoning engine.”
RAG = “knowledge plugin.”
Together, the agent is both smart + informed.
When to use
RAG only: If your use case is mostly about fetching + quoting facts (FAQs, docs, search).
Fine-tuning only: If your use case is about style, reasoning, or process (e.g., legal reasoning, summarization style).
RAG + fine-tuning: If you want accurate + aligned + dynamic agents → most enterprise use cases fall here.
💡 Typically, the rule of thumb is that fine-tuning is treated as a last resort.
Why? Because it’s expensive $$$ when you get that GCP bill in the mail…
Hyper-parameter tuning
Hyperparameter tuning is finding the best “settings” for an AI model so it performs as well as possible.
Hyper-parameter tuning for LLMs is less about squeezing out 1–2% accuracy (like in classic ML) & more about finding stability, efficiency, and alignment with your use case — both during training and at inference time.
🍭 Temperature
Think of it like how wild you want your candy choices to be.
If the temperature is low (close to 0) → you almost always grab the most common jellybean (safe, predictable, fixed, stable).
If the temperature is high (like 1 or more) → you might grab weird flavors too, like pickle or toothpaste (creative, surprise me :)
🍬 Top-K
The AI looks at all the jellybeans but only keeps the K most popular ones in the jar.
Example: If K = 3, and the top flavors are cherry, grape, and lemon, then you can only pick from those three—never from orange or blueberry.
Bigger K = more choices. Smaller K = fewer choices.
🍡 Top-P (aka nucleus sampling)
Instead of picking a fixed number, you pick jellybeans until the total ‘popularity’ adds up to P.
Example: If P = 0.9, you keep adding flavors until their combined popularity is 90%.
This way, sometimes you keep 2 flavors, sometimes 5—it depends on which ones are most popular.
It’s like saying: “Give me enough flavors so I cover most of what people like.”
🍓 Together
Temperature decides if you like being adventurous or safe.
Top-K is like saying: “Only show me the top K flavors.”
Top-P is like: “Only show me flavors that cover most of the popular ones.”
References
🔗 Daily Dose of DS — AI Agents The Illustrated Book: https://media.licdn.com/dms/document/media/v2/D4D1FAQEML1iMubpa0g/feedshare-document-pdf-analyzed/B4DZjWbZoSGsAY-/0/1755944175041?e=1756944000&v=beta&t=1Ya-EsiSPKmcXztkmAZuB0UeVTYKw4XhAru1QAgA2v8
🔗 Anthropic — Building Effective Agents: https://www.anthropic.com/engineering/building-effective-agents
🔗 Deeplearning.ai — Evaluating AI Agents: https://www.deeplearning.ai/short-courses/evaluating-ai-agents/
🔗 GPT-5 Prompting Guide: https://cookbook.openai.com/examples/gpt-5/gpt-5_prompting_guide
🔗 DataCamp — Fine-tuning Large Language Models: https://www.datacamp.com/tutorial/fine-tuning-large-language-models
🔗 Weaviate — Intro to RAG: https://weaviate.io/blog/introduction-to-rag
🔗 Wikipedia — Naive Bayes Classifier: https://en.wikipedia.org/wiki/Naive_Bayes_classifier
Who knew Deep Agents are so deep